Python抓包并解析json爬虫
在使用Python爬虫的时候,通过抓包url,打开url可能会遇见以下类似网址,打开后会出现类似这样的界面,无法继续进行爬虫:
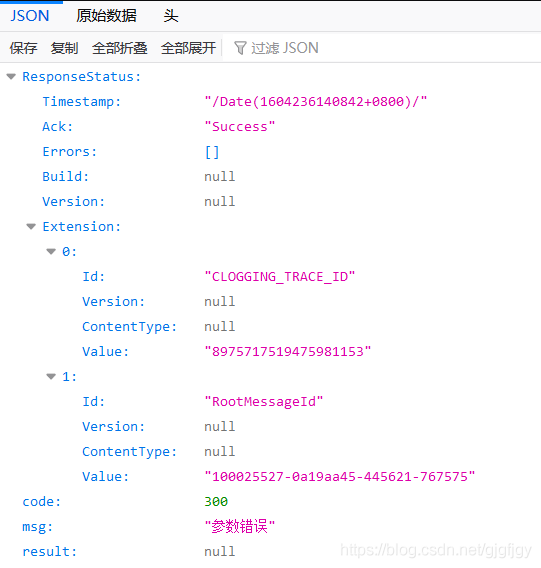
例如:
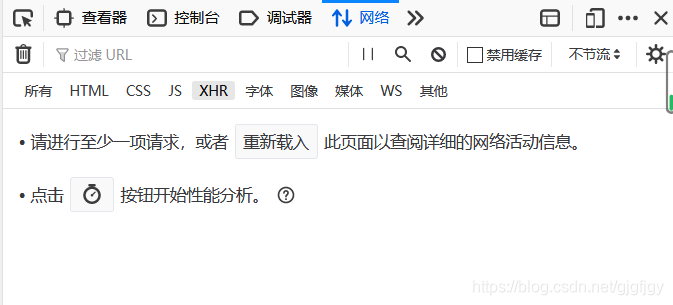
需要爬取网页中第二页的数据时,点击F12➡网络(Network)➡XHR,最好点击清除键,如下图:
通过点击“第二页”,会出现一个POST请求(有时会是GET请求),点击POST请求的url,(这里网址以POST请求为例),
如图:
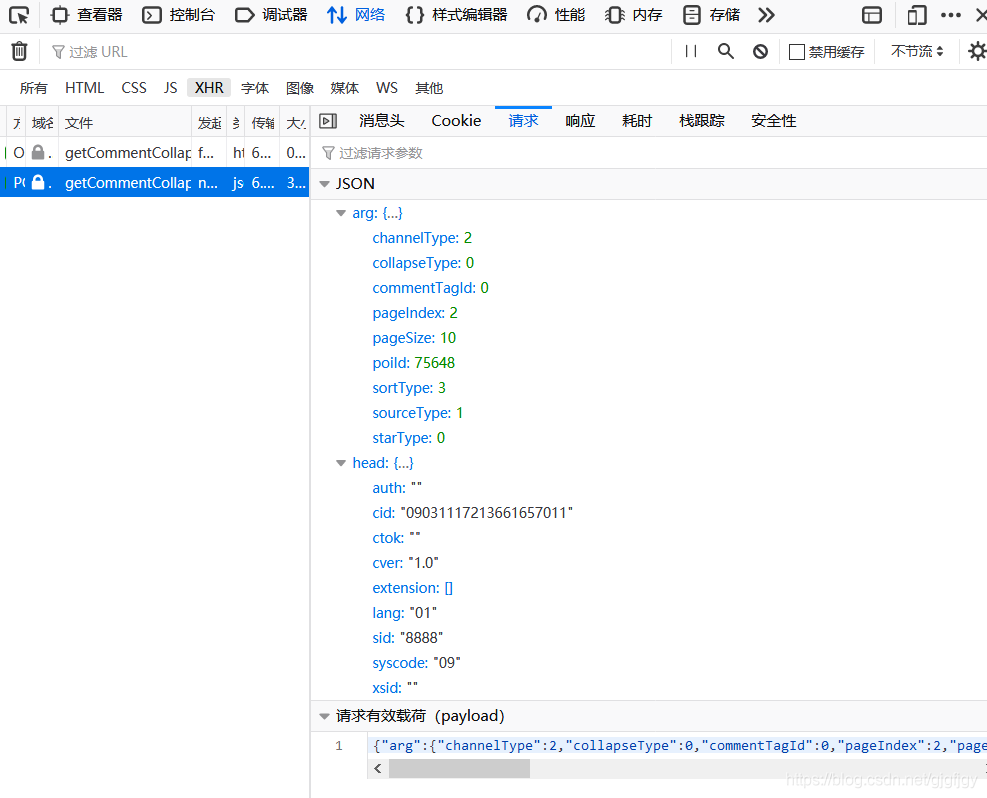
然后复制参数代码
代码展示:
import requests
import json
url = \'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031130211378497389\'
header={
\'authority\': \'m.ctrip.com\',
\'method\': \'POST\',
\'path\': \'/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031130211378497389\',
\'scheme\': \'https\',
\'accept\': \'*/*\',
\'accept-encoding\': \'gzip, deflate, br\',
\'accept-language\': \'zh-CN,zh;q=0.9\',
\'cache-control\': \'no-cache\',
\'content-length\': \'278\',
\'content-type\': \'application/json\',
\'cookie\': \'__utma=1.1986366783.1601607319.1601607319.1601607319.1; __utmz=1.1601607319.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); _RSG=blqD1d4mGX0BA_amPD3t29; _RDG=286710759c35f221c000cbec6169743cac; _RGUID=0850c049-c137-4be5-90b7-0cd67093f28b; MKT_CKID=1601607321903.rzptk.lbzh; _ga=GA1.2.1986366783.1601607319; nfes_isSupportWebP=1; appFloatCnt=8; _gcl_dc=GCL.1601638857.CKzg58XqlewCFQITvAodioIJWw; Session=SmartLinkCode=U155952&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=&SmartLinkLanguage=zh; Union=OUID=index&AllianceID=4897&SID=155952&SourceID=&createtime=1602506741&Expires=1603111540922; MKT_OrderClick=ASID=4897155952&AID=4897&CSID=155952&OUID=index&CT=1602506740926&CURL=https%3A%2F%2Fwww.ctrip.com%2F%3Fsid%3D155952%26allianceid%3D4897%26ouid%3Dindex&VAL={\"pc_vid\":\"1601607319353.3cid9z\"}; MKT_Pagesource=PC; _RF1=218.58.59.72; _bfa=1.1601607319353.3cid9z.1.1602506738089.1602680023977.4.25; _bfi=p1%3D290510%26p2%3D290510%26v1%3D25%26v2%3D24; MKT_CKID_LMT=1602680029515; __zpspc=9.5.1602680029.1602680029.1%232%7Cwww.baidu.com%7C%7C%7C%25E6%2590%25BA%25E7%25A8%258B%7C%23; _gid=GA1.2.1363667416.1602680030; _jzqco=%7C%7C%7C%7C1602680029668%7C1.672451398.1601607321899.1602506755440.1602680029526.1602506755440.1602680029526.undefined.0.0.16.16\',
\'cookieorigin\': \'https://you.ctrip.com\',
\'origin\': \'https://you.ctrip.com\',
\'pragma\': \'no-cache\',
\'referer\': \'https://you.ctrip.com/\',
\'sec-fetch-dest\': \'empty\',
\'sec-fetch-mode\': \'cors\',
\'sec-fetch-site\': \'same-site\',
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36\'
}
dat = {
\"arg\": {
\'channelType\': 2,
\'collapseType\': 0,
\'commentTagId\': 0,
\'pageIndex\': 1,
\'pageSize\': 10,
\'poiId\': 75648,
\'sortType\': 3,
\'sourceType\': 1,
\'starType\': 0
},
\"head\": {
\'auth\': \"\",
\'cid\': \"09031117213661657011\",
\'ctok\': \"\",
\'cver\': \"1.0\",
\'extension\': [],
\'lang\': \"01\",
\'sid\': \"8888\",
\'syscode\': \"09\",
\'xsid\': \"\"
}
}
r = requests.post(url, data=json.dumps(dat), headers=header)
s = r.json()
print(s)
运行结果:

然后右击结果,再点击Show as JSON:

最后就会出现目标url的响应信息,就可以进行爬取了!!!
总结
到此这篇关于Python抓包并解析json爬虫的文章就介绍到这了,更多相关Python抓包并解析json爬虫内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!












