1.首先读取Excel文件
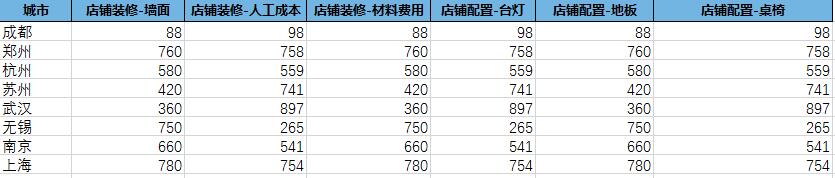
数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算;
2.pandas实现过程
import pandas as pd #1.读取数据 df = pd.read_excel(r\'./data/pfee.xlsx\') print(df)
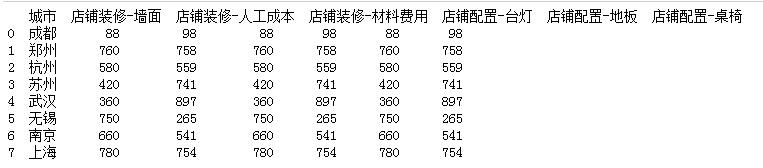
cols = list(df.columns) print(cols)

#2.获取含有装修 和 配置 字段的数据 zx_lists=[] pz_lists=[] for name in cols: if \'装修\' in name: zx_lists.append(name) elif \'配置\' in name: pz_lists.append(name) print(zx_lists) print(pz_lists)

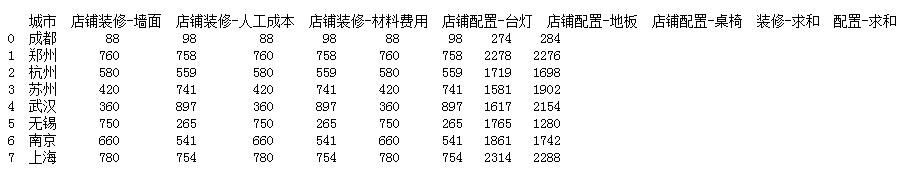
#3.对装修和配置项费用进行求和计算 df[\'装修-求和\'] =df[zx_lists].apply(lambda x:x.sum(),axis=1) df[\'配置-求和\'] = df[pz_lists].apply(lambda x:x.sum(),axis=1) print(df)
补充:pandas 中dataframe 中的模糊匹配 与pyspark dataframe 中的模糊匹配
1.pandas dataframe
匹配一个很简单,批量匹配如下
df_obj[df_obj[\'title\'].str.contains(r\'.*?n.*\')] #使用正则表达式进行模糊匹配,*匹配0或无限次,?匹配0或1次
pyspark dataframe 中模糊匹配有两种方式
2.spark dataframe api, filter rlike 联合使用
df1=df.filter(\"uri rlike \'com.tencent.tmgp.sgame|%E8%80%85%E8%8D%A3%E8%80%80_|android.ugc.live|\\ %e7%88f%e8%a7%86%e9%a2%91|%E7%%8F%E8%A7%86%E9%A2%91\'\").groupBy(\"uri\").\\ count().sort(\"count\", ascending=False)
注意点:
1.rlike 后面进行批量匹配用引号包裹即可
2.rlike 中要匹配特殊字符的话,不需要转义
3.rlike \’\\\\\\\\bapple\\\\\\\\b\’ 虽然也可以匹配但是匹配数量不全,具体原因不明,欢迎讨论。
In [5]: df.filter(\"name rlike \'%\'\").show() +---+------+-----+ |age|height| name| +---+------+-----+ | 4| 140|A%l%i| | 6| 180| i%ce| +---+------+-----+
3.spark sql
spark.sql(\"select uri from t where uri like \'%com.tencent.tmgp.sgame%\' or uri like \'douyu\'\").show(5)
如果要批量匹配的话,就需要在后面继续添加uri like \’%blabla%\’,就有点繁琐了。
对了这里需要提到原生sql 的批量匹配,regexp 就很方便了,跟rlike 有点相似
mysql> select count(*) from url_parse where uri regexp \'android.ugc.live|com.tencent.tmgp.sgame\'; +----------+ | count(*) | +----------+ | 9768 | +----------+ 1 row in set (0.52 sec)
于是这里就可以将sql中regexp 应用到spark sql 中
In [9]: spark.sql(\'select * from t where name regexp \"%l|t|_\"\').show() +---+------+------+ |age|height| name| +---+------+------+ | 1| 150|Al_ice| | 4| 140| A%l%i| +---+------+------+
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自学编程网。如有错误或未考虑完全的地方,望不吝赐教。












